【hadoop】yarn资源调度
本文共 1649 字,大约阅读时间需要 5 分钟。
文章目录
在hadoop1.0中
运行的时候有两个进程
- jobtracker 整个计算程序的老大 ( 负责资源调度,随机调度,监控程序运行的状态 ,启动运行程序)
- tasktracker 强行将计算资源分为两部分,mapslot 和 reduceslot, 每一部分资源只能跑对应的任务,资源并没有
缺陷:
- 单点故障
- 多有的程序资源调度是随机的(会造成资源浪费)
- 会造成jobtracker的运行压力过大
在hadoop2.0中mapreduce —> mapreduce + yarn
在hadoop2.0中
yarn在启动的时候有两个进程:
-
resourcemanager 整个资源调度的老大
- 接收客户端的请求(运行程序的请求)
- 接收nodemanaser的状态报告(包括nodemanager的资源状态,存活状态)
- 负责整个计算程序的资源调度(调度的运行资源和节点)
-
nodemanager 是负责真正的提供资源,运行计算程序的
- 接收resourcemanager的命令
- 提供资源运行计算程序
yarn启动计算以及资源调度:
- MRAppMaster:是单个计算程序的老大,
- 主要负责帮助档期计算程序向resourcemanager申请资源
- 负责启动maptask 和 reducetask任务
- 负责监控maptask和reducetask的运行进度
- ASM(aplications manager)所有应用程序的管理者: (ASM是resourcemanager中的)
- 主要负责调度应用程序
- container:抽象的资源容器(封装着一定的cpu 、io、网络资源)是运行maptask、reducetask 等的运行资源单位,一个maptask 最终会在一个容器中运行,当容器启动的时候显示的就是yarnchild
- scheduler:调度器(yarn的ResourceManager的组件) 调度的是什么时候计算那个计算程序,默认有三种调度器
- FIFO(先进先出):先提交的程序先执行,内部维护一个队列
- FARI(公平调度器): 大家平分资源运行 内部维护一个队列 假设初始有一个任务在执行,则该任务占的资源 100% 再来一个任务 ,则每个任务占50% 再来一个 每个占33.3%
- CAOICITY(计算能力调度器):内部维护多个队列 可以按需进行配置资源,多个队列之间进行资源分配(例如:两个任务的计算任务不同,可以用两个队列进行划分,任务量大的分配的资源多一点,任务少的相对少一点,在每个队列中执行先进先出)
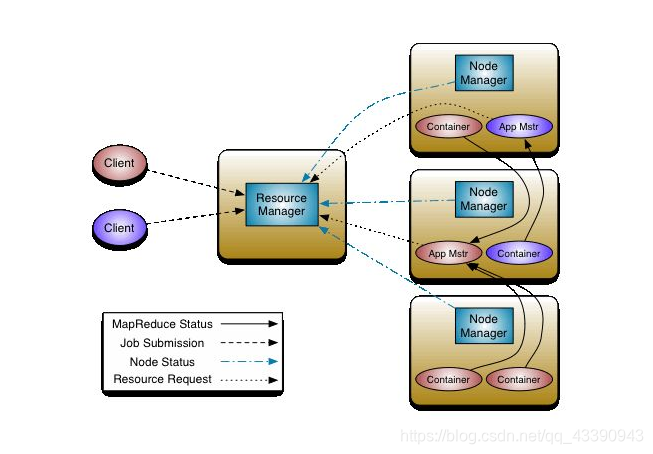
yarn的资源调度
- 客户端向ResourceManager发送请求
- ResourceManager中的ASM经过一系列的检查之后,将请求转发给Scheduler(调度器)
- 调度器给当前job分配资源,随机分配一个NodeManager
- ResourceManager在分配的NodeManager中先开启一个container(容器),再开启一个MrAppMaster
- MrAppMaster向ResourceManager申请资源,为maptask和reducetask运行使用
- ResourceManager向MrAppMaster 返回可供运行的NodeManager节点
- MrAppMaster在所有返回的NodeManager中先开启一个container(容器),再运行maptask任务
- 所有的maptask都会向MrAppMaster汇报自己的运行状态和进度
- 当所有的maptask的任务完成80%的时候,MrAppMaster开启reducetask任务(与maptask任务一样)
- 先在各个节点上开启一个container(容器),等到所有的maptask执行完成的时候,运行reducetask任务
- 在MrAppMaster检测到所有的任务都执行完成的时候,MrAppMaster进行资源回收并向ResourceManager申请注销自己
符一张图:
转载地址:http://ranwi.baihongyu.com/
你可能感兴趣的文章
Maven中指定得AspectJ依赖无法添加得解决方案
查看>>
Spring3注释装配的最佳实践
查看>>
Mac Vi常用键
查看>>
jchardet字符编码自动检测工具
查看>>
使用Maven Archetype生成工程报错的解决
查看>>
System.getProperty()系统参数
查看>>
Linux系统下批量删除.svn目录
查看>>
大数据行业应用趋势
查看>>
Mac + Rails3 + MongoDB的Demo工程搭建
查看>>
隐藏于Python内的设计之禅彩蛋
查看>>
VSCode配置C/C++环境
查看>>
OTB测试之Visual Tracker Benchmark v1.0全过程配置流程
查看>>
缓存在Springboot应用中的使用
查看>>
Linux(一)- 认识Linux
查看>>
Linux(二)- Linux常用命令
查看>>
Linux(三)- Java开发环境搭建
查看>>
Linux(四)- Ubuntu安装Mysql
查看>>
Ubuntu安装开发环境
查看>>
Deepin开发环境安装
查看>>
Spring入门
查看>>